학습 모델 및 데이터 신청 바로가기
한국어 BERT 언어모델
과학기술정보통신부와 IITP의 혁신성장동력 프로젝트로 추진 중인 엑소브레인 사업에서 한국어의 특성을 반영하여 개발한 BERT (Bidirectional Encoder Representations from Transformers) 언어모델을 공개합니다.
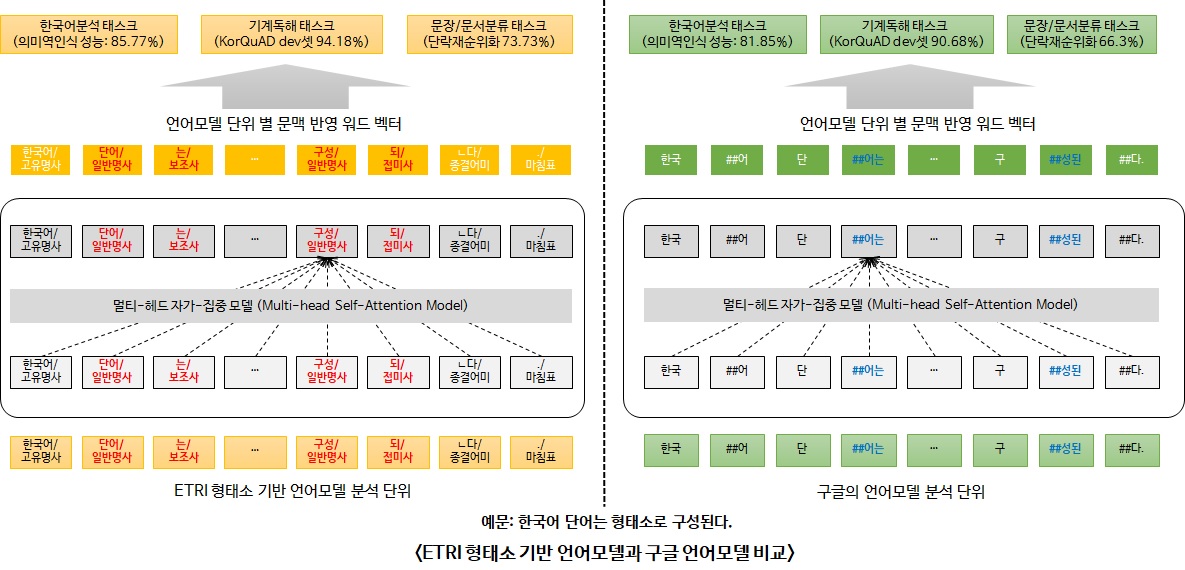
ETRI 엑소브레인 연구진이 배포하는 한국어 최첨단 딥러닝 언어모델은 한국어분석·기계독해·문서분류 등 다양한 태스크에 활용 가능하며, 5종(의미역 인식, 기계독해, 단락 순위화, 문장 유사도 추론, 문서 주제분류)의 한국어 처리 태스크에서 구글이 배포한 한국어 언어모델과 비교 평가한 결과, ETRI의 언어모델이 평균 4.5% 성능이 우수한 것으로 평가되었습니다.
BERT 언어모델은 대용량 원시 텍스트로부터 어휘의 양방향 문맥정보와 문장 간의 선후관계를 학습하여 단어를 문맥을 반영한 벡터로 표현하는 모델입니다. 한국어 언어모델 학습 말뭉치로는 신문기사와 백과사전 등 23GB의 대용량 텍스트를 대상으로 47억개의 형태소를 사용하여 학습하였습니다.
한국어 BERT 언어모델로 한국어의 특성을 반영한 형태소분석 기반의 언어모델과 형태소분석을 수행하지 않은 어절 기반의 언어모델 2가지 모델을 공개합니다.
- 형태소분석 기반의 언어모델은 교착어인 한국어의 특성을 반영한 모델입니다. 명사/동사에 조사/접미사가 결합된 어절을 의미의 최소단위인 형태소로 구분하여 분석한 언어모델로, 여러 태스크에서 어절 기반 언어모델 보다 우수한 성능을 보입니다. (형태소분석은 본 OpenAPI의 언어분석-형태소분석 API 이용)
- 어절 기반 언어모델은 구글과 유사한 방식으로 어절에서 고빈도로 발생하는 문자(음절)를 결합하여 단어를 구성한 언어모델로, 형태소분석을 수행하지 않아도 된다는 장점이 있습니다.
배포하는 언어모델은 대표적인 딥러닝 프레임워크인 파이토치(PyTorch)와 텐서플로우(Tensorflow)에서도 모두 사용 가능하도록 배포합니다. 활용을 위한 세부적인 내용은 다운로드 받은 언어모델 압축파일 내의 readme 문서를 참고하시면 됩니다.
| 배포 모델 | 세부 모델 | 세부 내용 | 모델 파라미터 |
|---|---|---|---|
| KorBERT | Korean_BERT_Morphology |
· 학습데이터: 23GB 원시 말뭉치 (47억개 형태소) · 형태소분석기: 본 OpenAPI 언어분석 중, 형태소분석 API · 딥러닝 라이브러리: pytorch, tensorflow · 소스코드: tokenizer 및 기계독해(MRC), 문서분류 예제 · Latin alphabets: Cased |
30349 vocabs, 12 layer, 768 hidden, 12 heads |
| Korean_BERT_WordPiece |
· 학습데이터: 23GB 원시 말뭉치 · 딥러닝 라이브러리: pytorch, tensorflow · 소스코드: tokenizer · Latin alphabets: Cased |
30797 vocabs, 12 layer, 768 hidden, 12 heads |
배포하는 한국어 KorBERT 언어모델의 구글 대비 평가 결과는 아래와 같습니다.
| - 의미역 인식(Semantic Role Labeling): 문장 내에서 술어에 의해 기술되는 사건에 대한 개체들의 역할을 인식 |
| - 기계 독해(Machine Reading Comprehension): 주어진 단락에서 질문이 요구하는 정답을 찾음 |
| - 단락 순위화(Passage Ranking): 검색결과 집합에서 질문에 찾는 정답이 들어있는 단락 순위화 |
| - 문장 유사도 추론(Natural Language Inference): 2개 문장 간 의미가 동일한 지 여부를 분류 |
| - 문서 주제분류: 문서의 주제를 기정의된 54개의 클래스 중 하나로 분류 |
| 구분 | 의미역인식 | 기계독해 | 단락순위화 | 문장유사도추론 | 문서주제분류 |
|---|---|---|---|---|---|
|
평가데이터 및 규격 |
Korean Propbank, 학습: 19,302 문장 평가: 3,773 문장 |
KorQuAD 데이터, 학습: 60,406건 평가: 5,773건 (dev셋) |
학습: 45,521 질문 평가: 1,000 질문 (질문당 평균 8.7개 단락) |
학습: 10,874 문장쌍 평가: 1,209 문장쌍 (이진 분류체계: 유사, 무관) |
학습: 9,301건 평가: 1,035건 (54개 분류체계) |
| 평가 방법 | F1[1] | Exact Match[[2]/F1 | Precision@Top1 | Accuracy | Accuracy |
|
(Google) Word Piece[3] 기반 한국어 언어모델 |
81.85% |
80.82% / 90.68% (정답 경계 구분을 위해 후처리 수행) |
66.3% | 79.4% | 91.1% |
|
(엑소브레인) Word Piece 기반 한국어 언어모델 |
85.10% |
80.70% / 91.94% (정답 경계 구분을 위해 후처리 수행) |
70.5% | 82.7% | 93.4% |
|
(엑소브레인) 형태소 기반 한국어 언어모델 |
85.77% | 86.40% / 94.18% | 73.7% | 83.4% | 93.7% |
[1] F1 : 정확률(Precision, 시스템이 결과가 정답인 비율)과 재현률(Recall, 실제 정답을 시스템이 맞춤 비율)의 조화평균
[2] Exact Match : 시스템이 제시한 결과와 정답이 완전히 일치하는 비율
[3] Word Piece : 하나의 단어를 내부 단어(Subword Unit)들로 분리하는 단어 분리 모델